网盾网络安全培训学校育,只培训技术精英
全国免费咨询电话: 15527777548/18696195380
前言
在企业安全建设专题中偶尔有次提到算法的应用,不少同学想深入了解这块,所以我专门开了一个子专题用于介绍安全领域经常用到的机器学习模型,从入门级别的SVM、贝叶斯等到HMM、神经网络和深度学习(其实深度学习可以认为就是神经网络的加强版)。
规则VS算法
传统安全几乎把规则的能力基本发挥到了极致,成熟企业的WAF、IPS、杀毒甚至可以达到两个九以上的准确度,很好的做到了"我知道的我都能拦截"。但是规则都是基于已有的安全知识,对于0day甚至被忽略的Nday,基本没有发现能力,即所谓的"我不知道我不知道",这时候算法或者说机器学习就发挥作用了,机器学习的优势就是可以从大量的黑白样本中,挖掘潜在的规律,识别出异常,然后通过半自动或者人工的分析,进一步确认异常是误报还是漏报。总之,精准判断入侵,不是机器学习的长项,识别漏报是一把好手。
scikit-learn是闻名遐迩的机器学习库,具有丰富的模型支持以及详细的在线文档,支持python语言,开发周期短,特别适合原理验证。scikit-learn
SVM支持向量机
SVM是机器学习领域使用最广泛的算法之一,通常用来进行模式识别、分类以及回归分析,它特别适合安全世界里面的非黑即白,所以我们重点介绍分类相关的知识。
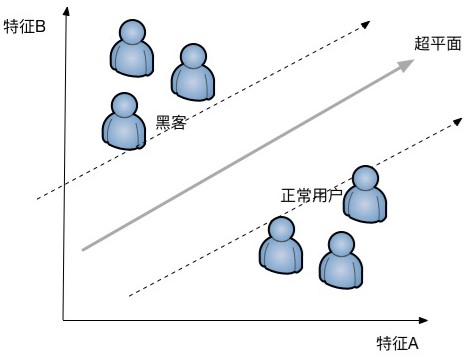
假设只有二维的特征向量,我们需要解决一个分类问题,需要通过将正常用户和黑客区分开来,如果确实可以通过一条直线区分,那么这个问题成为可以线性可区分(linear separable),如果不行则成为不可线性区分(linear inseparable)。讨论最简单的情况,假设这个分类问题是可以线性区分的,那么这个区分的直线成为超平面,距离超平面最近的样本成为支持向量(Supprot Verctor)。
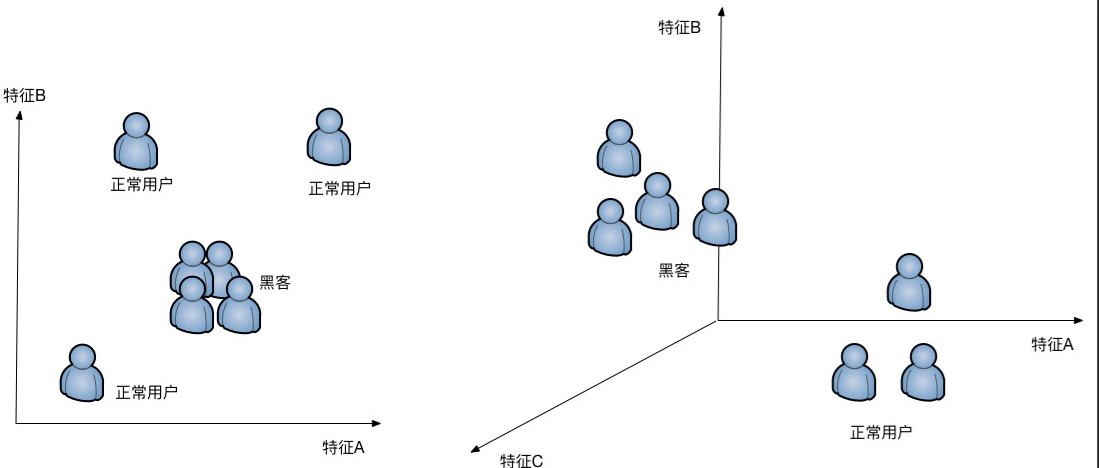
如上图,对于不可线性区分的情况,需要升级到更高的平面进行区分,比如二维平面搞不定就需要升级到三维平面来区分,这个升级就需要依靠核函数。
监督学习与无监督学习
监督学习(supervised learning)简单讲是拿标记过的数据去训练;无监督学习(unsupervised learning)简单讲是拿没有标记的数据去训练,SVM训练时需要提供标记,所以属于监督学习。
监督学习的一般步骤
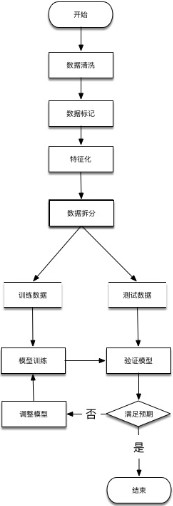
由于我们的例子比较简单,把上述两个步骤合并即可,准备数量相等的正常web访问日志和XSS攻击的web日志,最简单的方法是参考我以前的文章《基于WAVSEP的靶场搭建指南》,使用WVS等扫描器仅扫描XSS相关漏洞即可获取XSS攻击的web日志。数据搜集&数据清洗
特征化
实践中数据搜集&数据清洗是最费时间的,特征化是最烧脑的,因为世界万物是非常复杂的,具有很多属性,然而机器学习通常只能理解数字向量,这个从现实世界的物体转变成计算世界的数字的过程就是特征化,也叫向量化。比如要你特征化你前女友,你总不能说漂亮、温柔这些词,需要最能代表她的特点的地方进行数字化,下面是一个举例:
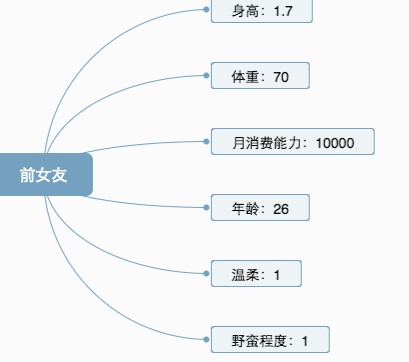
你会发现各个向量之间的数据范围差别很大,一个月消费能力可能就干掉其他特征对结果的影响了,虽然现实生活中这个指标确实影响很大,但是不足以干掉其他全部特征,所以我们还需要对特征进行标准化,常见的方式为:
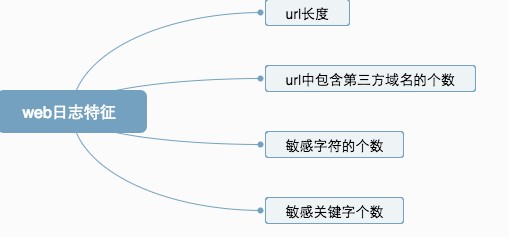
数据打标
数据拆分
数据训练
通过加载训练后的模型,针对测试集合进行预测,将预测结果与打标结果比对即可。模型验证
clf=joblib.load("xss-svm-200000-module.m")
y_test=[]
y_test=clf.predict(x)
print metrics.accuracy_score(y_test, y)
测试环节我们在一个各有200000个样本黑白模型上训练,在一个各有50000个样本的黑白测试集上校验,任何黑白预测错都判断为错误,最后运行结果准确度率为80%,对于机器学习而言,仅依靠模型优化,这个比例已经很高了。通过在更大的数据集合上进行训练(比如大型CDN&云WAF集群的日志),进一步增加特征个数以及增加后面环节的自动化或者半自动化的验证,可以进一步提高这个比例,最后准确率我们做到了90%以上。下图是特征扩展的举例,大家可以根据实际情况增加。
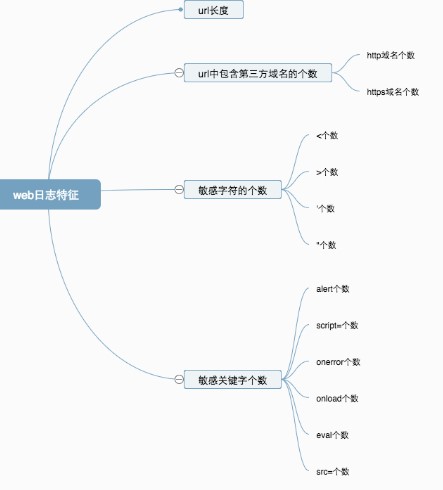
异常数据
不少人问过我,"什么样的情况下可以用算法?"。这个没有一个统一的答案,我认为在规则、沙箱都做的比较到位的情况下,可以试着使用机器学习;如果是已知漏洞都没有很好的防御和检测的话,使用机器学习确实性价比低。汽车在刚出来的时候没有马车快,但是是选择造一辆更快的马车还是选择造属于未来的汽车,这个见仁见智。总结